ML is the field of study that gives computers the ability to learn without being explicitly programmed
Supervised vs. Unsupervised Machine Learning
Supervised Learning
x -----> y
input output label
Learns from being given “right answers” (We provide enough examples with input x along with corresponding output label y from which the machine learns. Eventually, when we give an new input without output label, it’ll generate the output by itself based on the learning)
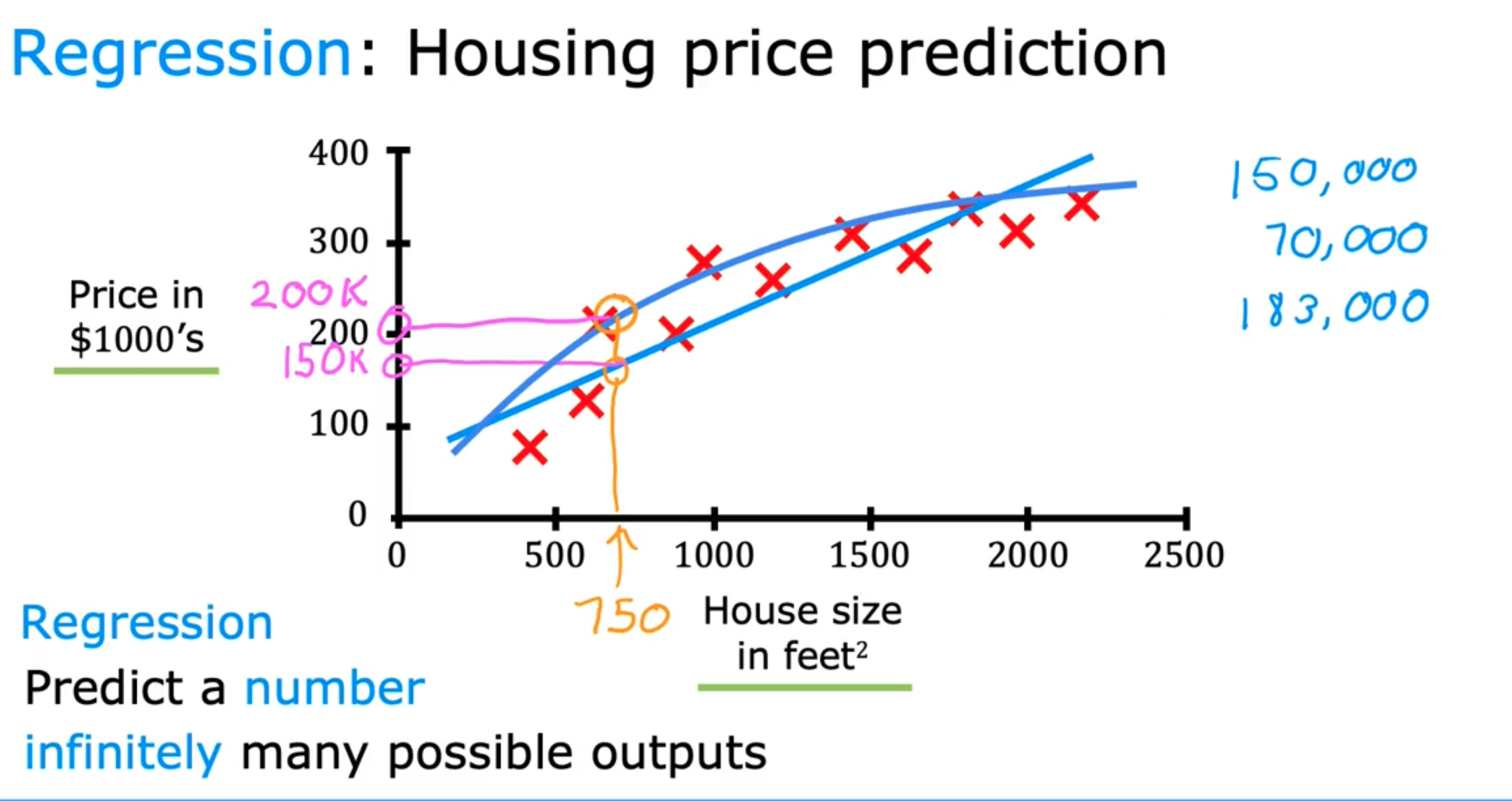
Regression
Type of Supervised Learning that predicts a number (There could be infinitely many possible outputs)
Housing price prediction (Given a set of House size with the corresponding Price for it, we make the algorithm to fit a curve along the given points, now when we need the price for a new house with a randomly input House size, we can get the value from the point of intersection of the curve)
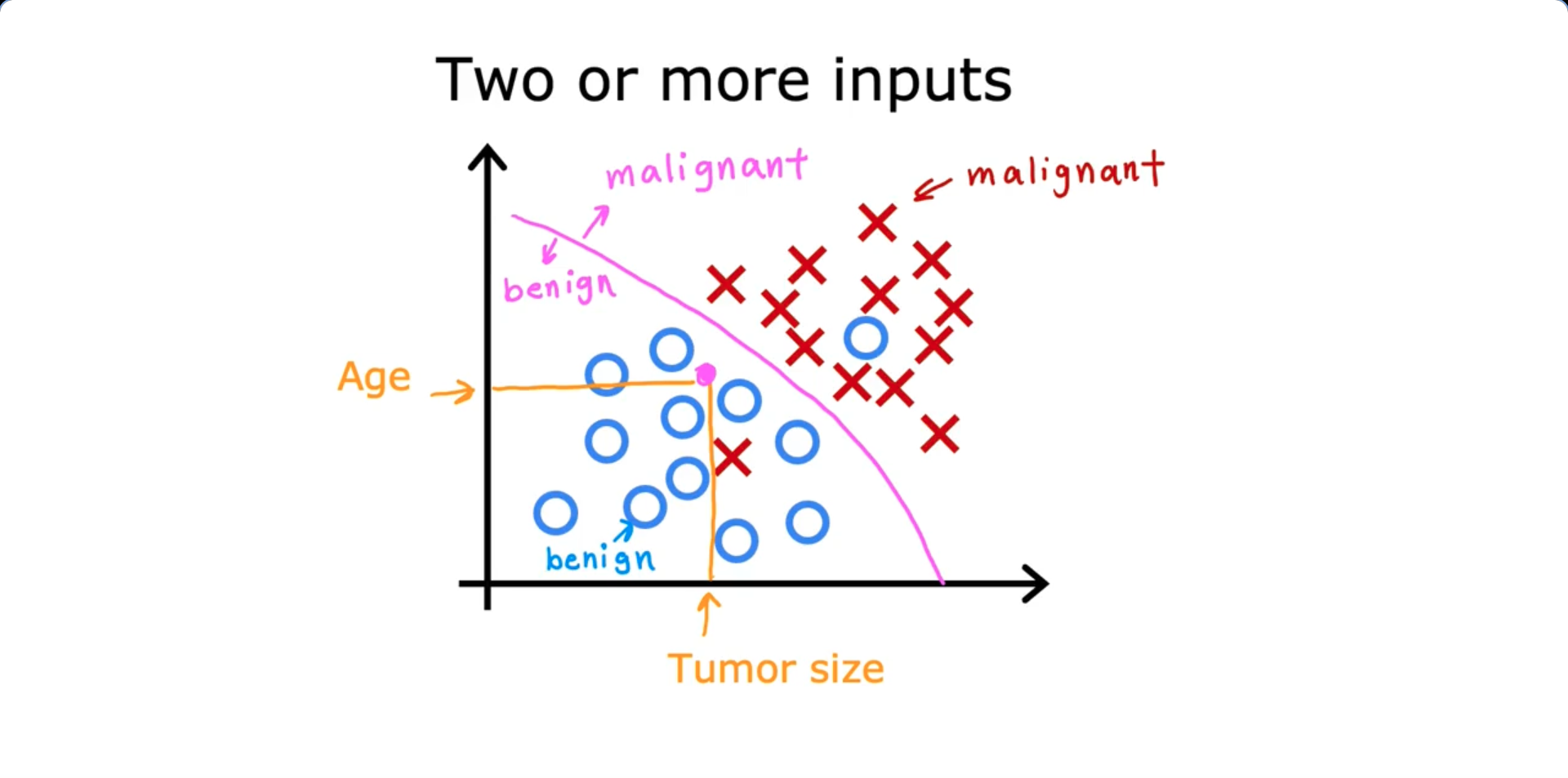
Classification
We use classification to predict only a small number of possible outcomes/ categories (Ex: Predict if a tumor is malignant or benign based on it’s size)
- Classification predict categories (Cat or Dog; Benign or Malignant; 0 or 1 or 2). The learning algorithm sets a boundary line for the given data for classification
Unsupervised Learning
Find something interesting in unlabeled data (We only provide input x, not output labels y). We let the algorithm to search for a structure in the input data
Clustering
The algorithm groups the unlabeled similar input data into clusters.>
Following are some examples:
- Google News (Clustering of similar news)
- DNA microarray (Clustering of people with similar DNA characteristics)
Anomaly Detection
Find unusual data points
Dimensionality Reduction
Compress data using fewer numbers
Regression Model
Linear Regression Model
This is a Supervised learning model. Linear regression is one of the regression models. Predicts numbers
Terminology
Data used to train the model = Training Set
x = “input” variable (feature)
y = “output” variable (target)
ŷ = modles predicted value
y = true or observed value of the dependent variable
m = number of training examples
(x, y) = single training example
(x, y) = i^t$$^h training example
+-------------------+
| Training Set |
+-------------------+
|
v
+-------------------+
| Learning Algorithm|
+-------------------+
|
v
+----------------+
x ----> | f(x) Function | ----> ŷ
(feature) +----------------+ (prediction)
Example:
+-----+
size (x) ----> | f | ----> price (ŷ - estimated)
+-----+

Cost Function: Squared Error cost function
A mathematical function that measures the difference between a model’s predictions and the actual values
The cost function ( J(w, b) ) is defined as:
The goal is to find ( w, b ) such that:
Visualizing the cost function
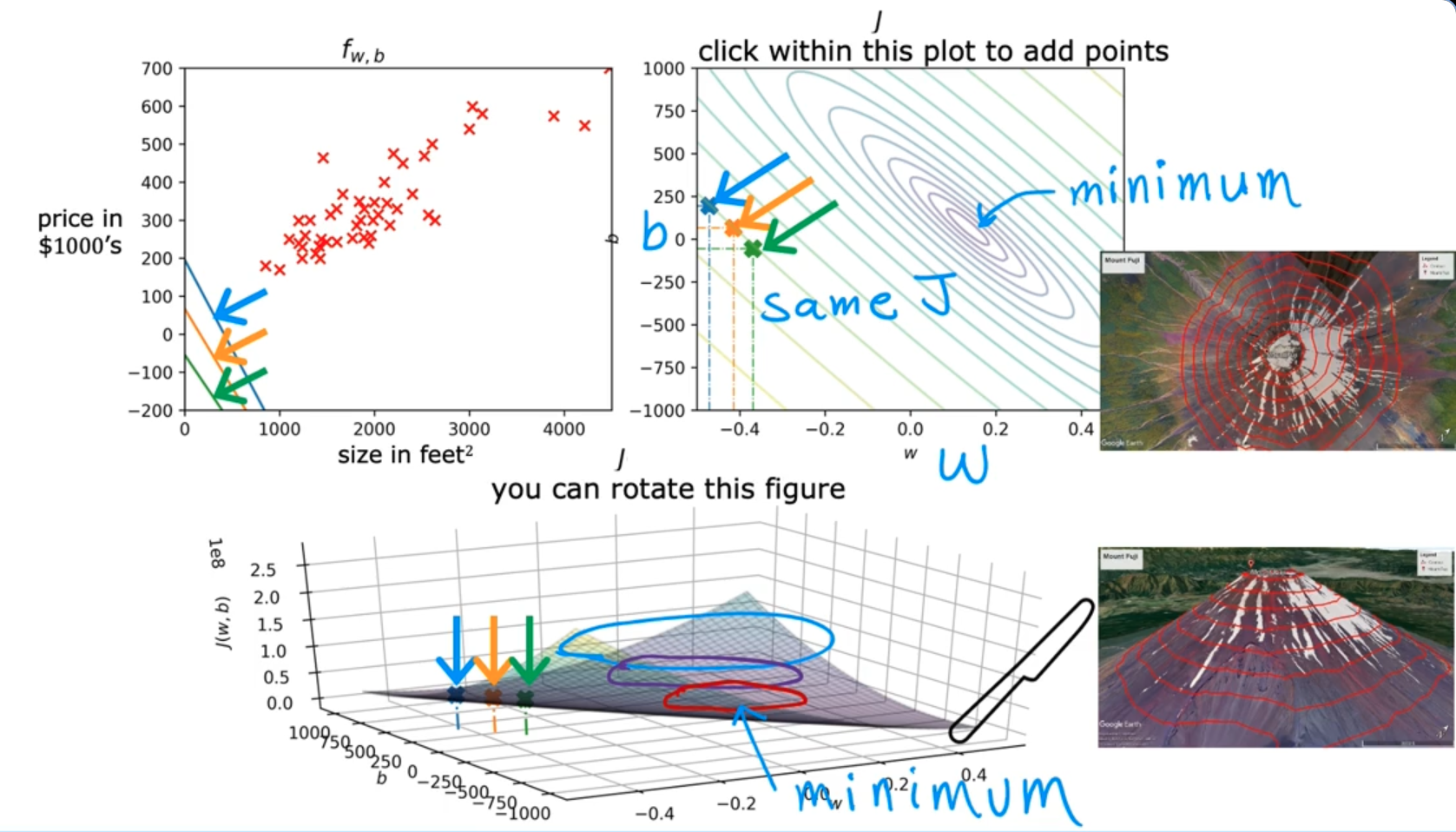
- When we represent the cost function with two input parameters (w, b) we’ll get a 3D shape
- The height of any point corresponding to w and b values will be the Cost Function value (The higher the point, higher the value of cost function)
- To represent the cost function in 2D, we use the Contour plot graph which appears to be the sliced version of the 3D plot (The smallest oval shape represents the minimum value of the Cost Function)
- For Linear Regression models, there will be only one Local Minimum ~ Global Minimum. However, for other models, there’ll be multiple local minima and the one with the lowest value will be the Global Minimum
Gradient Descent
Algorithm to minimize a function (Cost Function in our case)
- Start with some w, b (Set w=0, b=0 as the initial guess)
- Keep changing w, b to reduce J(w, b) (Simultaneously update w and b)
- Until we settle at or near a minimum
- In the algorithm below, we use Batch Gradient descent because each step of gradient descent uses all the training examples (i.e i=1 to i=m)
Gradient Descent Algorithm
Repeat until convergence:
Where:
- is the learning rate
- is the derivative of the cost function with respect to
- is the derivative of the cost function with respect to
Formula after calculating the derivative Repeat until convergence:
Where:
- is the hypothesis(Models’ prediction function)
- is the learning rate
- is the number of training examples
- is the training example
Multiple Linear Regression
Multiple Features
We represent each training example with multiple input features. Let:
Hypothesis for Multiple Linear Regression
Vectorization
- Makes the code shorter
- Makes the code run much faster (NumPy library uses parallel hardware either CPU or GPU)
Let’s consider the following data
w = np.array([1.0,2.5,-3.3])
b = 4
x = np.array([10,20,30])Code to find f(x) without vectorization (Option 1)
f = w[0] * x[0] +
w[1] * x[1] +
w[2] * x[2] + bCode to find f(x) without vectorization (Option 2)
f =0
for j in range(0,n):
f = f + w[j] * x[j]
f = f + bCode with Vectorization
f = np.dot(w,x) + bGradient Descent for Multiple Linear Regression
Gradient descent now becomes as follows:
Alternative to gradient descent
Normal Equation
- Only for linear regression
- Solve for w, b without iterations Disadvantages
- Doesn’t generalize to other learning algorithms
- Slow when number of features is large (> 10,000) What we need to know
- Normal equation method may be used in machine learning libraries that implement linear regression
- Gradient descent is the recommended method for finding parameters w,b
Gradient Descent in Practice
Feature Scaling
- When the possible range of values of a feature is large (House size in sq. feet x1 = 300 to 2,000), it’s more likely that a good model will choose a small parameter value (w1 = 0.1)
- When the possible range of values of a feature is small (No. of bedrooms x2 = 0 to 5), it’s more likely that a good model will choose a large parameter value (w2 = 50)
- But, when we have different features that take on different range of values, it can cause gradient descent to run slowly. But, rescaling different features so that they can all take comparable range of values can speed up gradient descent computation much faster
Divide the range by max value
Mean Normalization
Feature ranges
Mean values (Of all the values of the feature)
Normalization formulas
Labels
Z-score Normalization
Ranges before normalization
Mean and standard deviation
Z-score formulas
Labels
Feature Engineering
Using intuition to design new features, by transforming or combining original features
- Let’s take the problem of finding price of house given two features x1(Frontage) and x2(Depth)
- We can include a third feature x3(Area) = x1(Frontage) (x) x2(Depth) to enhance the model performance
Polynomial Regression
Fitting non-linear function (Curves). Given a single feature x, we can make it a quadratic, cubic equation etc. for a better fit (Gives a curve instead of a straight line model)
Quadratic Model
Cubic Model
Square Root
Classification with Logistic Regression
Binary classification - The output can only be one of two values(Class / Category) (e.g either yes or no)
Logistic Regression
We want outputs between 0 and 1, so we use the sigmoid (logistic) function:
Define:
Then the logistic regression model is:
If the logistic regression model gives a probability that the output is 1:
This is interpreted as:
If:
Then there’s a 70% chance that ( y = 1 ) (i.e., malignant).
Since this is a binary classification:
Decision Boundary
Set a threshold above which the result will be considered 1 and 0 if below
Here is how we can decide on the decision boundary:

Cost function for Logistic Regression
- The Squared error cost function we used for Linear regression(Gives a bowl shape - convex function) doesn’t work well for Logistic Regression (Gives Non-convex graph)
Logistic Cost Function
Logistic Loss Function
Simplified Cost Function
Gradient Descent Implementation
The problem of Overfitting
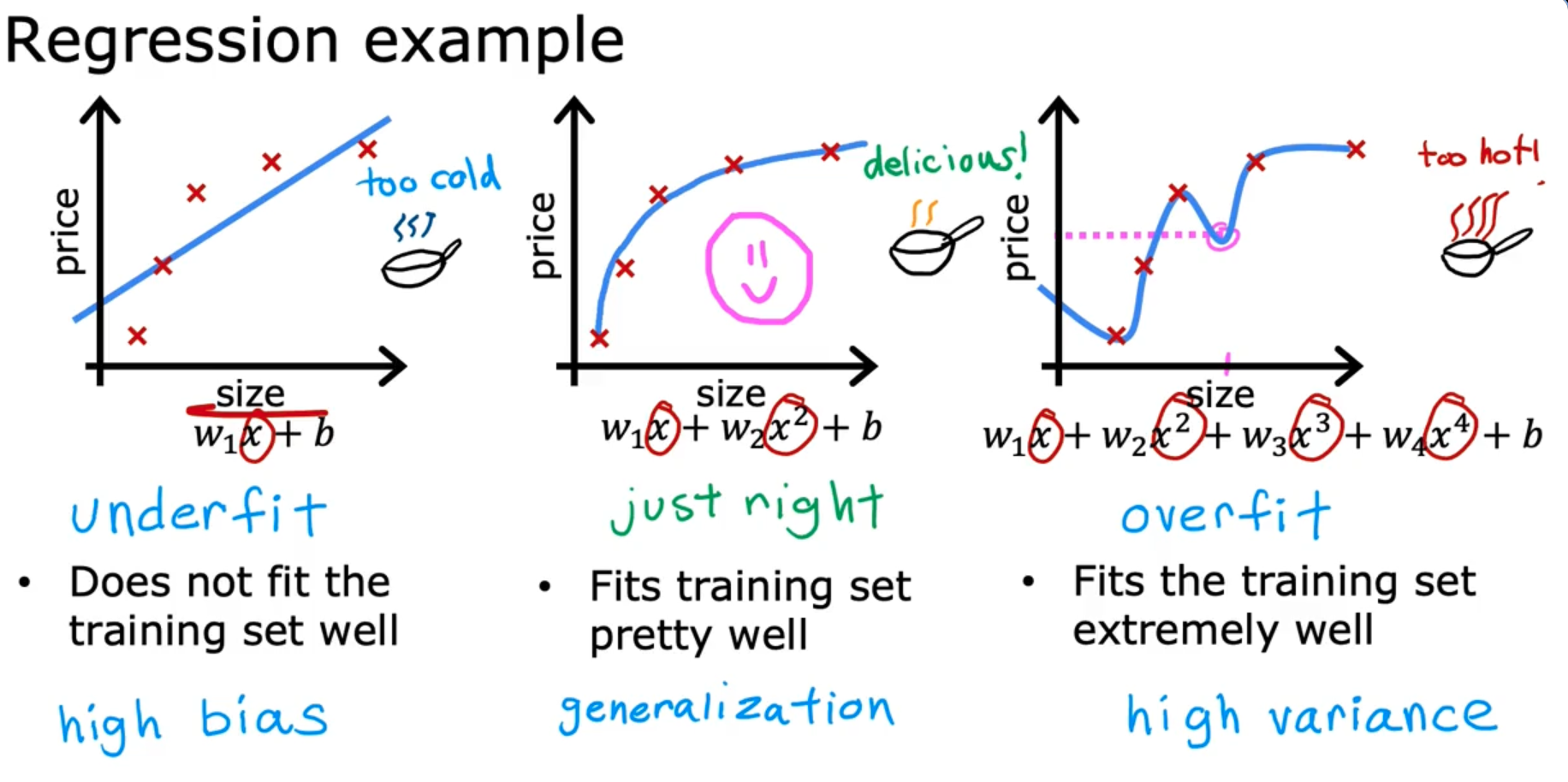
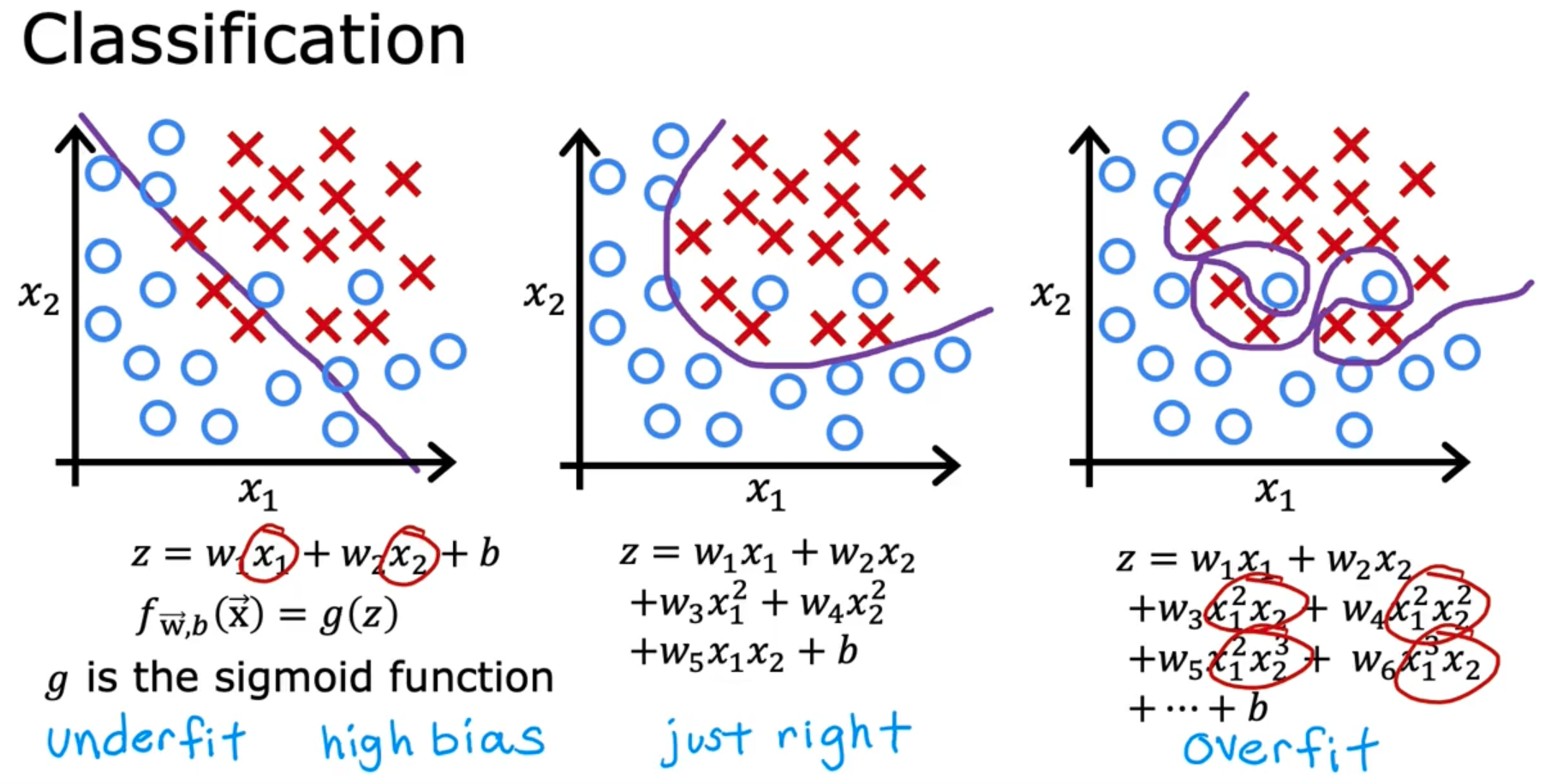
Addressing Overfitting
- Collect more training data (The learning algorithm will learn to fit better)
- Select features to include/ exclude (Feature selection : Choose the most relevant features)
- Regularization (Shrink the values of parameters instead of altogether removing the features like discussed in the previous step)
Cost Function with Regularization
- The first term: Mean squared error (MSE) – fits the data.
- The second term: L2 regularization – penalizes large weights to reduce overfitting.
- lambda: Regularization strength – balances fit vs simplicity.
Regularized Linear Regression
🔹 Regularized Cost Function
🔹 Gradient Descent Updates
For the bias term 𝑏 (not regularized):
Regularized Logistic Regression
🔹 Regularized Cost Function
🔹 Gradient Descent Updates
For the bias term