Clustering
Looks at a number of data points and automatically finds data points that are related or similar to each other
Applications :
- Grouping similar news
- Market segmentation
- DNA analysis
- Astronomical data analysis
K-means Clustering algorithm
Repeatedly do:
- Assign point to cluster centroids
- Recompute cluster centroids (To average of all points that were assigned to it )

Optimization Objective
K - means is guaranteed to converge (On every single iteration, the distortion cost function should go down or stay the same. If it ever goes up, it means there is a bug in the code. If the value doesn’t change in the next iteration, it also means K - means has converged)
Initializing K-means
Very first step of K-mean is to choose random locations as the initial guesses for the cluster centroids. How to do it best?
- Choose K < m
- Randomly pick K training examples
- Set (μ1, μ2, …, μk) the centroids equal to these K examples
Choosing the number of clusters (K)
- Often, we want to get clusters for some later (downstream) purpose
- Evaluate K-means based on how ell it performs on that later purpose
For example, in a T-shirt size clustering algorithm:
- We could have K = 3 (Three sizes - S, M, L)
- Or, we could have K = 5 (Five sizes - XS, S, M, L, XL) We need to compare both by evaluating them in the business perspective and decide which is better accordingly. For example, having 3 sizes rather than 5 has lower cost production and transportation wise. But, having 5 sizes gives a better fit for users and might satisfy them
Anomaly Detection
Given a collection of events, finding unusual events is Anomaly Detection
Gaussian (Normal) Distribution
Mean :
Variance:
Anomaly Detection Algorithm
- Choose n features xᵢ that we think might be indicative of anomalous examples
- Fit parameters μ₀, μ₁,…,μ and σ, σ,…, σ
- Given new example x, compute p(x):
Developing and evaluating an anomaly detection system
Also known as real-number evaluation
- Have a few labelled data in the Cross-validation and Test sets of data. After fitting the anomaly detection model, evaluate it with the cross-validation and test sets to find out whether the algorithm is detecting the example as anomaly or not and compare this result with the label
- Use this evaluation to tune the epsilon(Threshold above which an entry is not an anomaly) value
- Can possibly consider evaluation metrics like Precision/Recall also
Anomaly Detection vs. supervised learning
Anomaly detection
- Can be preferred when having very small number of positive examples (y=1). (0-20 is common). Large number of negative (y=0) examples.
- Many different “types” of anomalies. Hard for any algorithm to learn from positive examples what the anomalies look like; future anomalies may look nothing like any of the anomalous examples we’ve seen so far
- Fraud detection
- Manufacturing - Finding new previously unseen defects in manufacturing
- Monitoring machines in a data center
Supervised Learning
- Can be preferred when having large number of positive and negative examples
- Enough positive examples for algorithm to get a sense of what positive examples are like, future positive examples likely to be similar to ones in training set
- Email spam classification
- Manufacturing - Finding known, previously seen defects
- Diseases classification
Choosing what features to use
More important task for anomaly detection
- The features must be guassian (Plotting the features should give a gaussian graph). If not, try to make them gaussian (Probably by using np.log(x) or log(x +1) or sqrt(x) etc.). These transformations makes the anomaly detection model better. Also, make sure to make the same transformation to cross-validation and testing data as well
Error analysis for anomaly detection
- Train a model, then see what anomalies in the cross-validation set that the algorithm is failing to detect. Then, look into those examples and see if that can inspire the creation of new features that would allow the model to spot that example which takes on unusually large or small value on the new features and classify whether it’s an anomaly or not
Recommender System
- System with a set of users and items (Movie ratings for example)
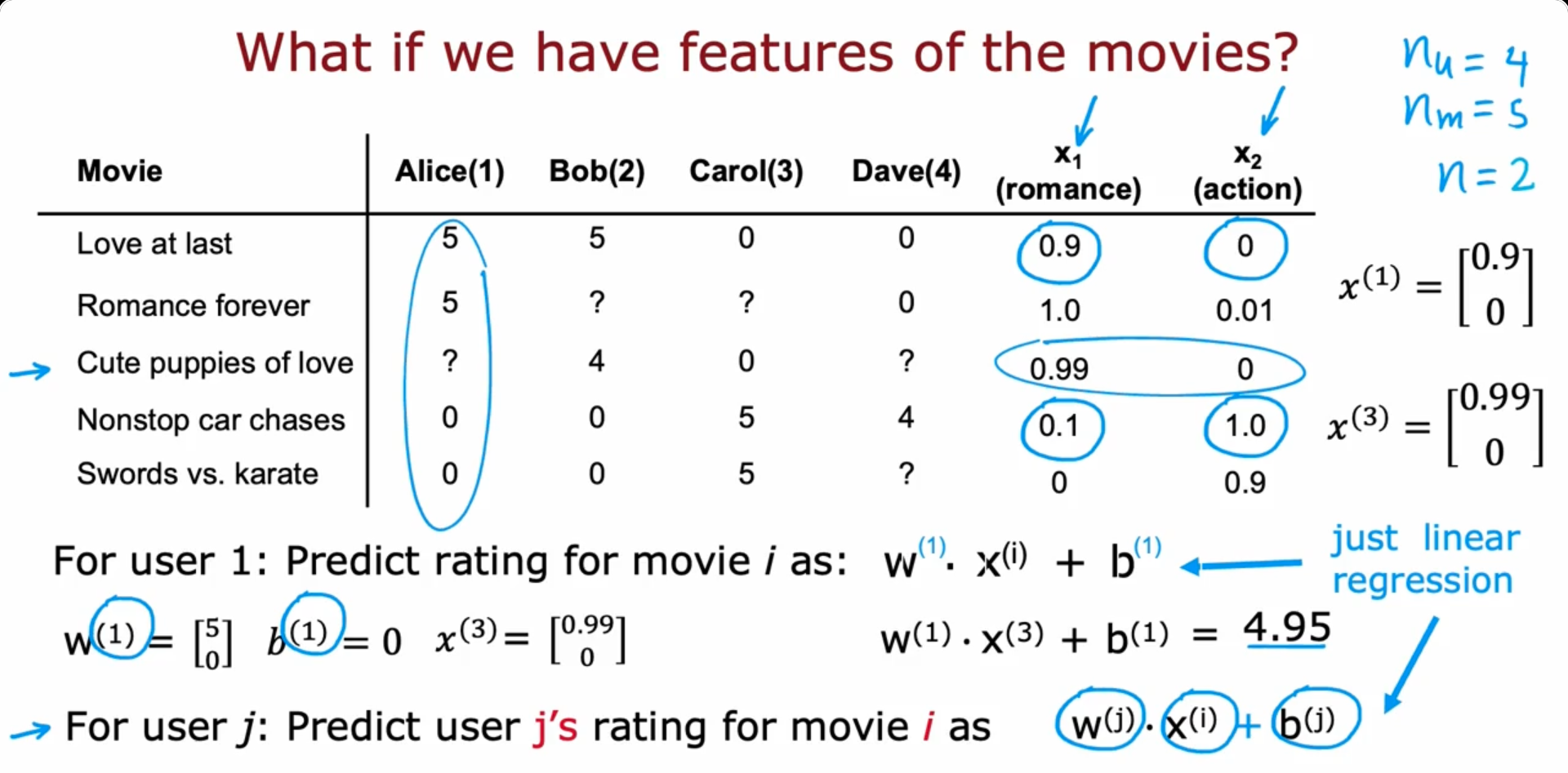
Collaborative filtering algorithm
- In the above example, we’ve got two features x and x for each movie
- In some cases, let’s say only the ratings are provided and the features aren’t given. We have to find the features ourselves
Cost function to learn w, b for all users
Cost function to learn x for all movies
Combining both together
We have to reduce the cost function. Gradient descent algorithm can be used for this purpose, the following are the updating steps in each iteration :
Binary labels: favs, likes and clicks
Binary prediction function :
Predict that the probability of y = 1
Binary Cross-Entropy Loss for One Example:
Total Cost Over All Observed Ratings:
Recommender systems implementation
Mean Normalization

TensorFlow implementation
Getting the derivative term of cost function with TensorFlow
Gradient Descent
w = tf.Variable(3.0) # Tf.variables are the parameters we want to optimize
x = 1.0
y = 1.0 #target value
alpha = 0.01
iterations = 30
for iter in range(iterations):
# Use TensorFlow's Gradient tape to recored the steps
# used to compute the cost J, to enable auto differentiation.
with tf.GradientTape() as tape:
fwb = w*x # Assuming b=0 for this example
costJ = (fwb=y)**2
# Use the gradient tape to calculate the gradients
# of the cost with respect to the parameter w.
[dJdw] = tape.gradient(costJ, [w])
# Run one step of gradient descent by updating
# the value of w to reduce the cost.
w.assign_add(-alpha * dJdw) # tf.variables require special function to modifyAdam Optimizer algorithm
# Instantiate an optimizer
optimizer = keras.optimizers.Adam(learning_rate = 1e-1)
iterations = 200
for iter in range(iterations):
# Use TensorFlow's GradientTape to record
# the operations used to compute the cost
with tf.GradientTape() as tape:
# Compute the cost (forward pass is included in cost)
cost_value = cofiCostFuncV(X, W, B, Ynorm, R,
num_users, num_movies, lambda)
# Use the gradient tape to automatically retrieve the gradients of
# the trainable variables with respect to the loss
grads = tape.gradient(cost_vale, [x,W,b])
# Run one step of gradient descent by updating the
# value of the variables to minimize the loss.
optimizer.apply_gradients(zip(grads, [x,W,b]))Content-based filtering
Collaborative filtering vs Content-based filtering
Collaborative Filtering : Recommend items to you based on ratings of users who gave similar ratings as you
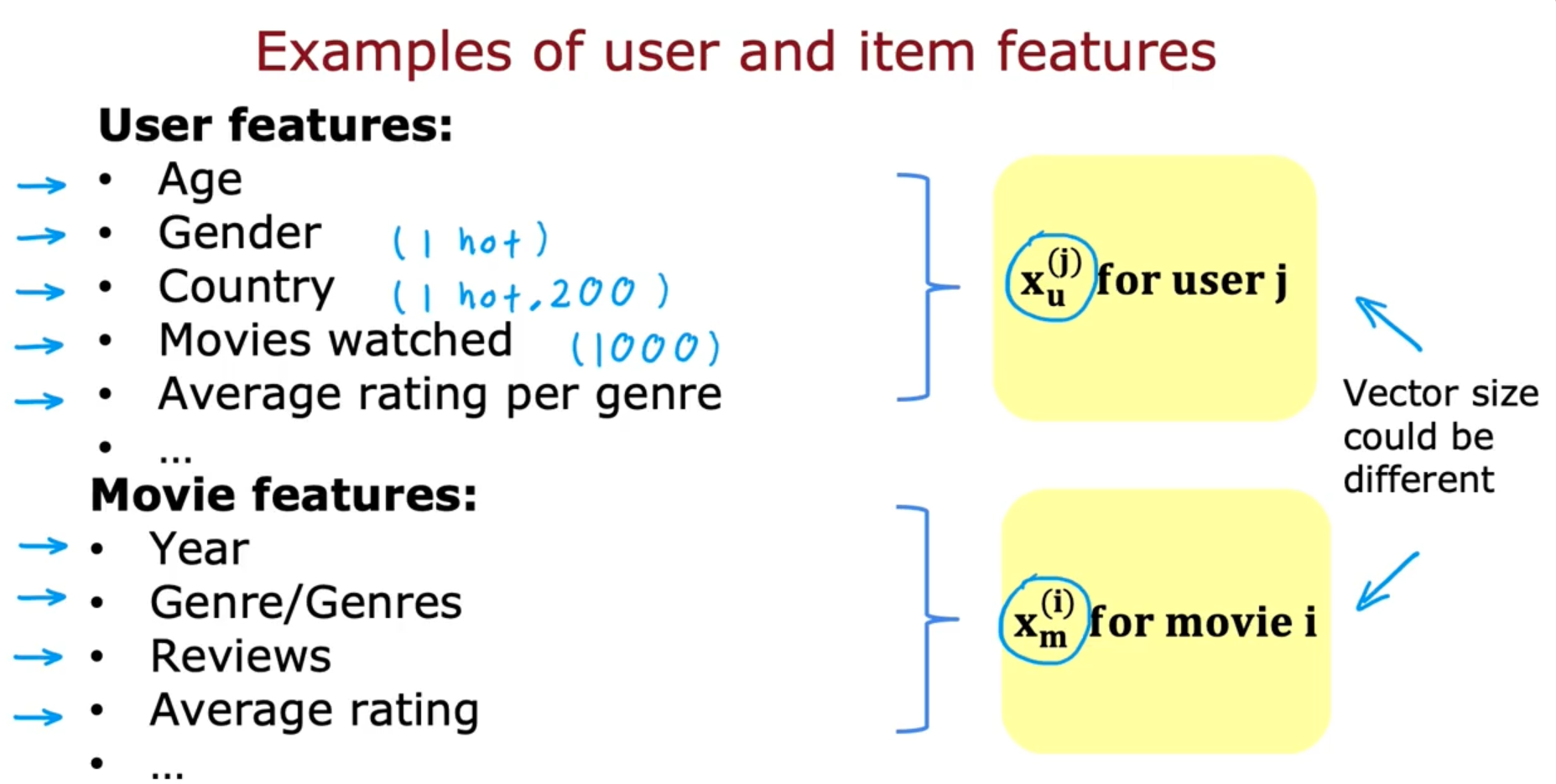
Content-based filtering : Recommend items to you based on features of user and item to find good match. We’ll still continue to make use of r(i, j) and y
Example of the usr and movie features :
Deep learning for content-based filtering
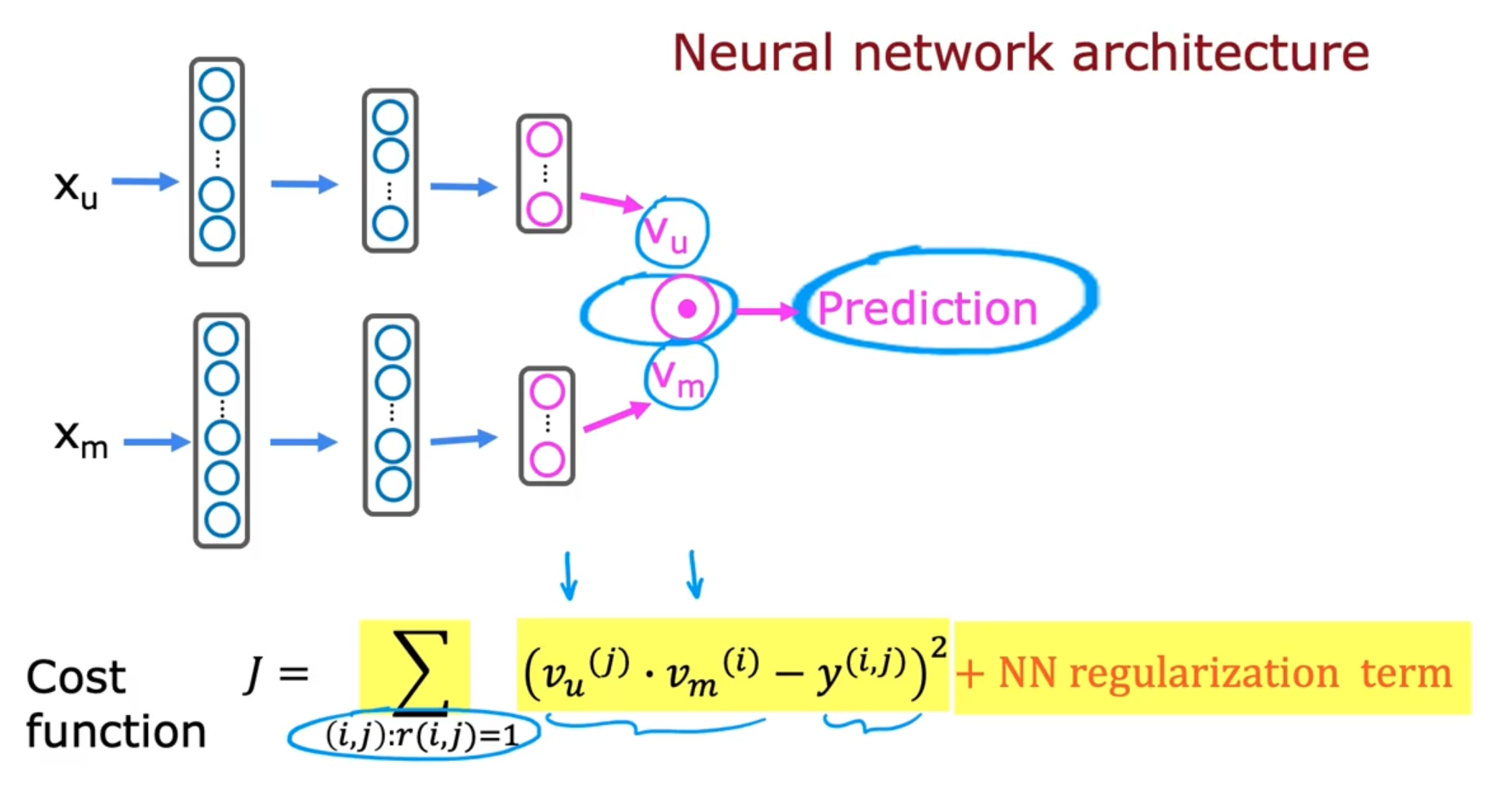
Learned user and item vectors:
Recommending from a large catelogue
How to efficiently find recommendation from a large set of items ? (It might be computationally inefficient to run neural network inference thousands of millions of times every time user shows up in a website )
Many large scale recommender systems are implemented in two steps as shown below: Retrieval :
- Generate large list of plausible item candidates (For example,)
- For each of the last 10 movies watched by the user, find 10 most similar movies
- For most viewed 3 genres, find the top 10 movies
- Top 20 movies in the country
- Combine retrieved items into list, removing duplicates and items already watched/purchased
Ranking :
- Take list retrieved and rank using learned model
- Display ranked items to user
- Retrieving more items results in a better performance, but slower recommendations. Based on our preference, we need to do find a trade-off point between the two
Principal Component Analysis
Used for visualization, specifically for dataset with a lot of features that cannot be plotted easily. PCA takes thousands of features, reduces it to two or three and then help to plot the features
PCA Algorithm
- Find axis z(Principal component) to retain variance (info)
- Find the projection points and use them as the new feature value
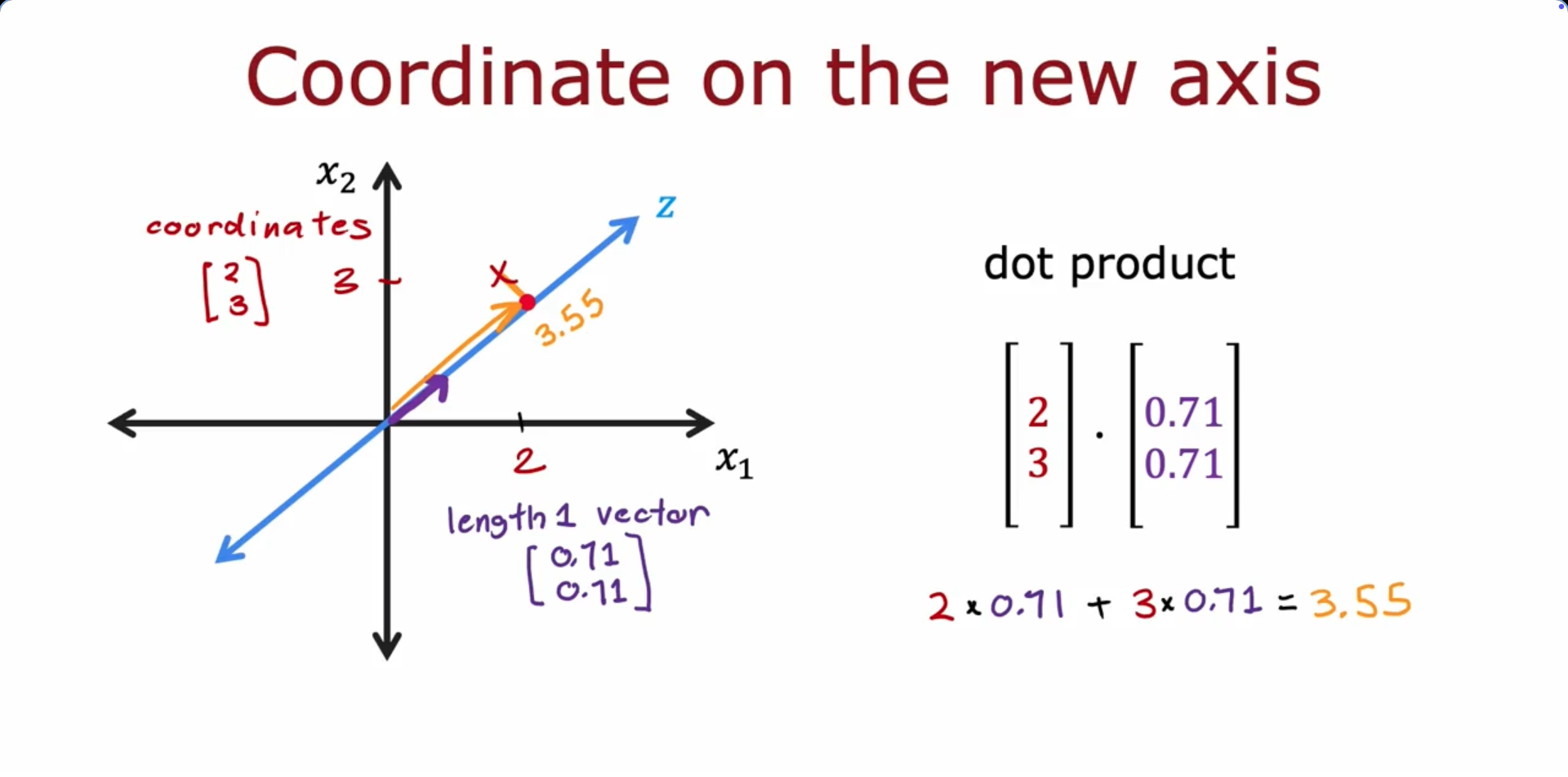
- Given a z value, we can use reconstruction to find the original (x, x)
Reinforcement Learning
What is Reinforcement Learning ?
A model learns to make decisions by interacting with an environment and receiving rewards or penalties for its actions
The Return in reinforcement learning
- The return is the sum of rewards that the system gets, weighted by the discount factor, where the rewards in a far future are weighted by a discount factor raised to a higher power
- If there are any rewards that are negative, then the discount factor will actually incentivize the system to push out the negative rewards as far into the future as possible (Applicable in financial applications)
Policy
In Reinforcement learning, our goal is to come up with a function which is called a policy (π) whose job is to take input state (S) and map it to action (a) that it wants us to take
- Find a policy π that tells you what action (a = π(s)) to take in every state (s) so as to maximize the return
Markov Decision Process (MDP) - Indicates that the future only depends on the current state and not on anything that might have occurred prior to of getting to current state
.png)
State-action value function
Q(s, a) = Return if we
- Start in state s.
- take action a (once)
- then behave optimally after that
The best possible return from state s is max Q(s, a) The best possible action in state s is the action a that gives max Q(s, a)

Bellman Equation
Helps us to calculate the state action value function Q(s, a)
Q(s, a) = Return if we
- Start in state s.
- take action a (once)
- then behave optimally after that
: current state
= reward of current state
: current action
: state you get to after taking action
: action that you take in state
Random (stochastic) environment
At times, in case of a stochastic environment, our Mars Rover may not exactly follow the action that we are asking it to take from a particular state. For example, it might slip and move right due to environmental factors though we command it to move left
- In such cases, we take the Expected Return (Average Return)
Continuous state spaces
- In case of a helicopter the following values are continuous. The state of a problem isn’t just one of a small number of possible discrete values (Ex: 1-6). Instead, it’s a vector of numbers any of which could take any values
- Position x, y, z
- Roll, Pitch, Yaw
- Speed in x, y, z directions
- Rate of turning (Angle of velocity) of Roll, Pitch, Yaw
Lunar Lander
Actions :
- do nothing
- left thruster (Moves to the right)
- Main thruster (Located at the bottom)
- right thruster (Moves to the left)
Reward Function :
- Getting to landing pad: 100-140
- Additional reward for moving toward/away from pad
- Crash: -100
- Soft Landing: +100
- Leg grounded: +10
- Fire main engine: -0.3
- Fire side thruster: -0.03
Goal :
- Learn a policy that, given
picks action so as to maximize the return. ()
Learning the state-value function
DQN - Deep Q Network
- Initialize neural network randomly as guess of
- Repeat{ Take actions in the lunar lander. Get Store 10,000 most recent tuples → Reply Buffer (Storing recent tuples) }
- Train neural network: Create training set of 10,000 examples using and Train such that ~ y Set
Algorithm Refinement
Improved neural network architecture
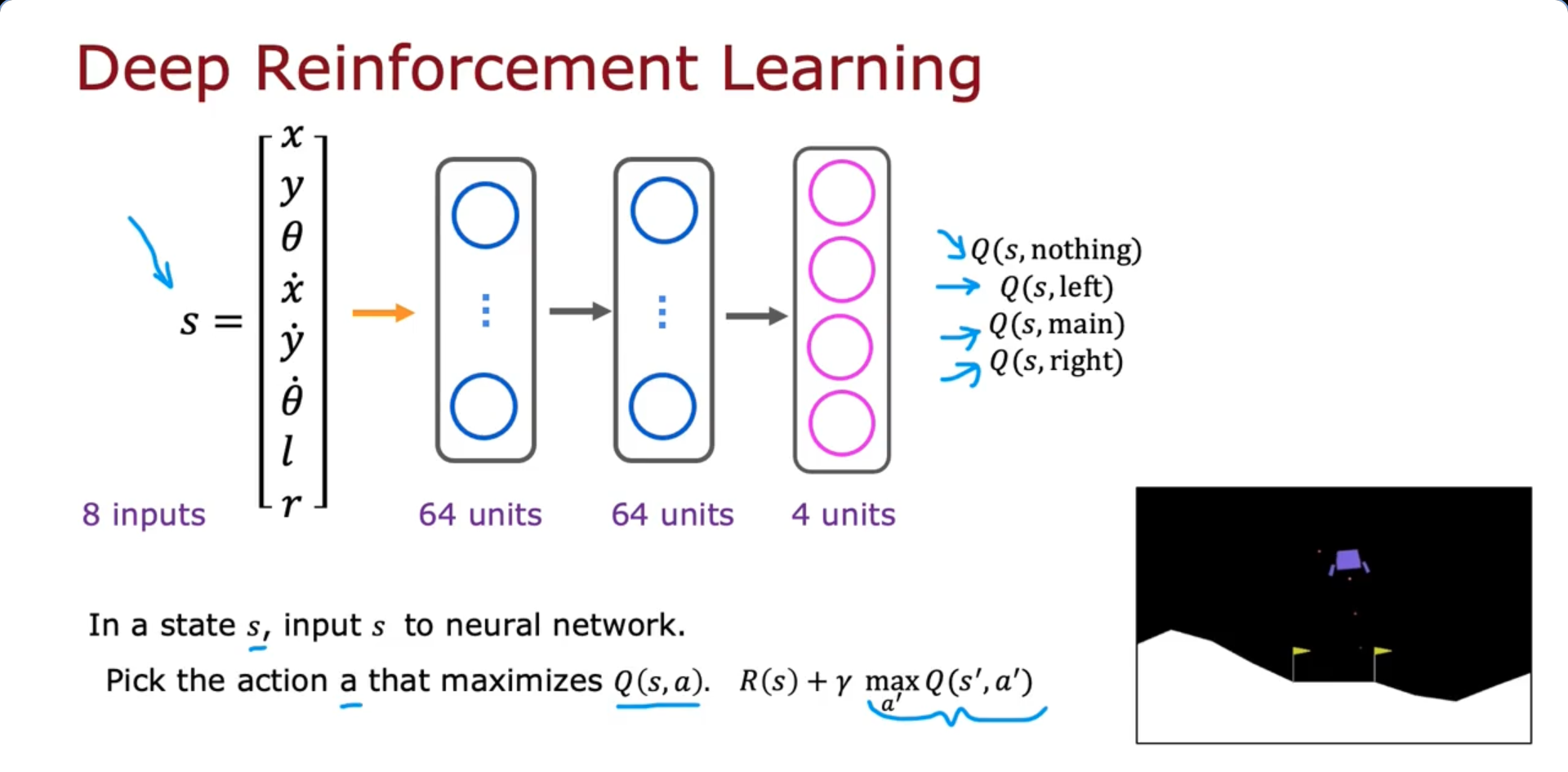
- In our previous architecture, with an input of 12 values, whenever we are in a state s, we would have to carry out inference separately four times to compute these four values , , , in order to pick the action that give the largest Q value. But, this is in-efficient because we have to carry out inference from every state four times
- It turns out to be more efficient to train a single neural network to output all four of the values simultaneously as shown in the above image
ε - greedy policy
How to choose action while still learning ?
In some state s Option 1: Pick the action a that maximizes
Option 2:
- With probability 0.95, pick the action a that maximizes → Referred to as Greedy step or Exploitation step
- With Probability 0.05, pick an action randomly (Suppose the was initialized randomly so that the learning algorithm thinks firing the main thruster is never a good idea, the neural network parameters may be initialized such that is very low. If that’s the case, the neural network will never ever pick the action of firing the main thruster since it has a very low Q, thus it won’t ever learn that firing the main thruster is actually a good idea in case we follow only Option 1) → Referred to as Exploration step or ε - greedy policy (ε = 0.05)
- It’s common to start ε high and Gradually decrease so that eventually we are taking greedy actions mostly and random actions rarely
Mini-batch and soft update
Mini-batch
- In our Housing price prediction algorithm,
repeat {
}
- Taking the the Gradient-descent algorithm update step to consideration, in each step, we take summation of samples. When value is too large, the summation might be computationally expensive. So, instead of , we take random entries from the sample during each updating step to enhance the algorithm
- Similarly, in our Reinforcement Learning Algorithm, we store most recent tuples.
- While training the model, we create the training set of examples alone instead of examples which speeds up the entire process
Soft-update
- Abruptly updating the value to might affect the algorithm in case turns out to be a bad value
- Making more gradual change to or to update the original neural network parameters is a better choice
Instead, update as follows :
The state of reinforcement learning
Limitations of Reinforcement Learning
- Much easier to get to work in a simulation than a real robot
- Far fewer applications than supervised and unsupervised learning
- But, exciting research direction with potential for future applications